Machine learning is no longer just a buzzword – it’s the engine powering everything from recommendation systems to self-driving cars. But behind this powerful technology lies a simple idea: teaching machines how to learn from data.
For an ML enthusiast (or an aspiring one), understanding the different types of machine learning is essential. Each type represents a unique way of learning, solving problems, and making decisions. Whether it’s predicting outcomes, uncovering hidden patterns, or learning through trial and error, these approaches form the backbone of modern AI systems.
In this article, we’ll explore the three core types of machine learning – supervised, unsupervised, and reinforcement learning – through a practical data science lens, breaking down how they work and where they are used in the real world.
Why Are There Different Types of Machine Learning?
At first glance, machine learning might seem like a single unified concept – feed data, train a model, and get results. However, in practice, not all data or problems are the same. This is where the different types of machine learning come into play.
The way a machine learns largely depends on the kind of data available and the objective we are trying to achieve. In some cases, we have clearly labeled data, where each input comes with a correct answer. In others, the data is completely unstructured, and the goal is to uncover hidden patterns or relationships. There are also scenarios where a system must learn through interaction with its environment, improving its decisions over time based on feedback.
Because of these varying situations, machine learning is broadly categorized into different types – each designed to handle a specific kind of problem. Understanding these distinctions not only helps in choosing the right approach but also in building more efficient and accurate models.
Types of Machine Learning
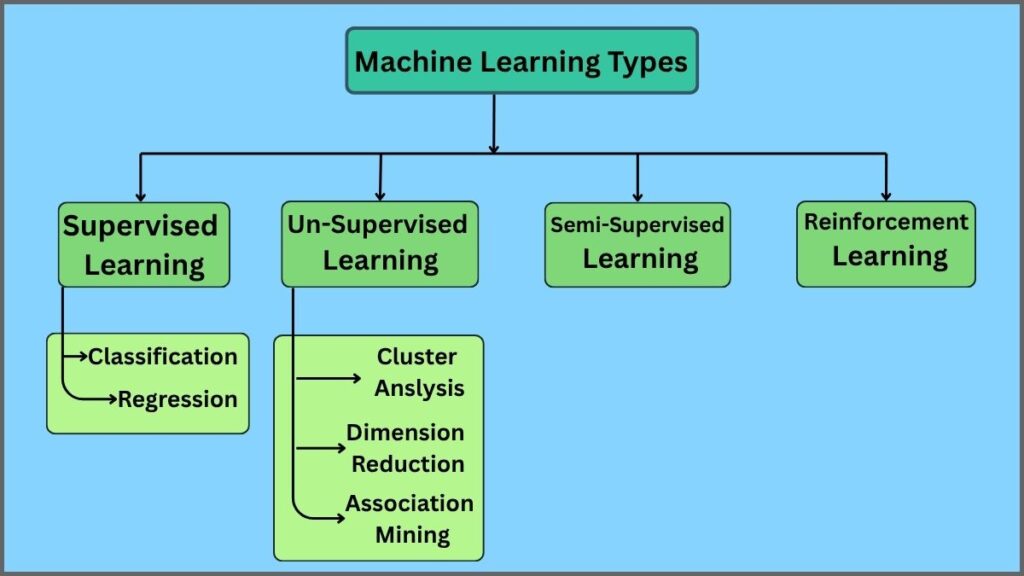
1. Supervised Learning
Supervised learning is the most widely used and well-understood type of machine learning. At its core, it is based on a simple idea: learning from labeled data. In this approach, a model is trained on a dataset where both the input features and the correct outputs are already known. The goal is to learn a mapping function that can accurately predict outputs for new, unseen data.
The concept of supervised learning dates back to early developments in pattern recognition and statistics during the mid-20th century. Techniques like linear regression and classification algorithms laid the foundation, which later evolved with advancements in computational power and data availability.
How does it work?
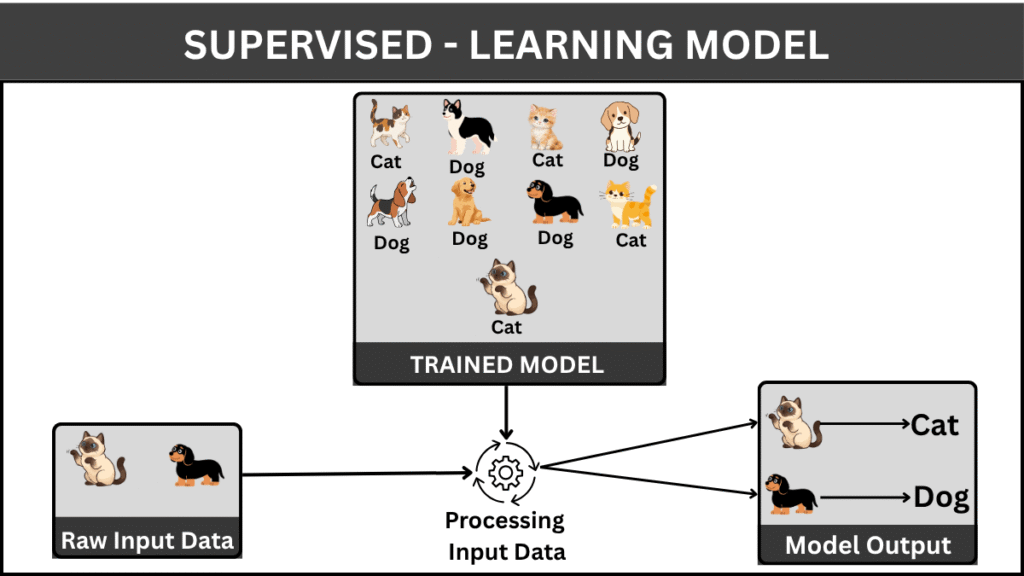
In supervised learning, the dataset is typically divided into two parts: a training set and a testing set. The model learns patterns from the training data and is then evaluated on the testing data to measure its performance. The learning process involves minimizing the difference between predicted outputs and actual outputs, often referred to as the “error.”
Some examples are Linear Regression, Logistic Regression, and Decision Trees
Types of Supervised Learning
Supervised learning problems are generally divided into two main categories:
Classification: Used when the output variable is categorical (e.g, spam vs. not spam, disease vs. no disease).
Regression: Used when the output variable is continuous (e.g., predicting house prices, temperature, or stock values).
When to Use Supervised Learning
Supervised learning is most effective when:
- You have a well-labeled dataset
- The problem involves prediction or classification
- Historical data is available and reliable
2. Unsupervised Learning
Unlike supervised learning, unsupervised learning deals with data that has no predefined labels. The model is not given the correct answers but instead must explore the data and identify patterns, structures, or relationships on its own. This makes unsupervised learning particularly powerful for discovering hidden insights in complex datasets.
The roots of unsupervised learning can be traced back to early statistical methods and clustering techniques developed in the mid-20th century. With the rise of big data, its importance has grown significantly, as much of the data generated today is unstructured and unlabeled.
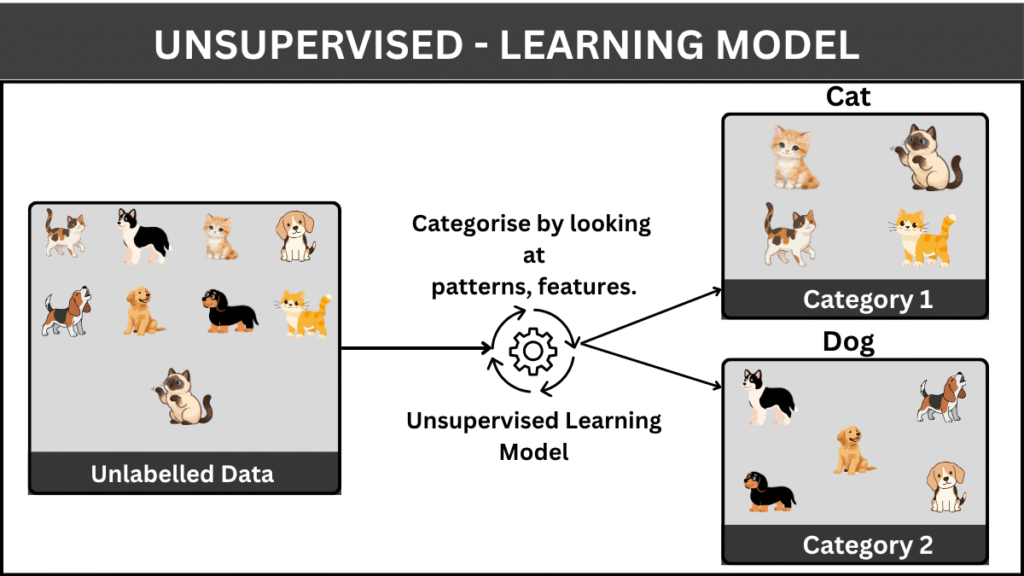
How does it work?
In unsupervised learning, the model analyzes input data and attempts to group or organize it based on similarities, differences, or underlying patterns. Since there are no labels, the evaluation of the model is often more subjective and depends on how meaningful the discovered patterns are. Some examples are K-Means Clustering, Hierarchical Clustering, DBSCAN, and Apriori Algorithm
Types of Unsupervised Learning
Unsupervised learning is commonly divided into the following categories:
- Clustering:
The goal is to group similar data points together. For example, customer segmentation based on purchasing behavior. - Association:
Focuses on discovering relationships between variables in large datasets (e.g., market basket analysis—items frequently bought together). - Dimensionality Reduction:
Used to reduce the number of features while preserving important information, making data easier to visualize and process.
When to Use Unsupervised Learning
Unsupervised learning is most useful when:
- You do not have labeled data
- You want to explore and understand data patterns
- The goal is to discover hidden structures or groupings
3. Semi-Supervised Learning
Semi-supervised learning sits between supervised and unsupervised learning, combining the strengths of both approaches. In many real-world scenarios, obtaining labeled data is expensive and time-consuming, while unlabeled data is abundant. Semi-supervised learning leverages a small amount of labeled data along with a large pool of unlabeled data to build better-performing models.
This approach gained prominence in the late 1990s and early 2000s as researchers began addressing the challenges of limited labeled datasets. With the explosion of data in the modern era – especially in domains like image recognition and natural language processing – semi-supervised learning has become increasingly relevant.
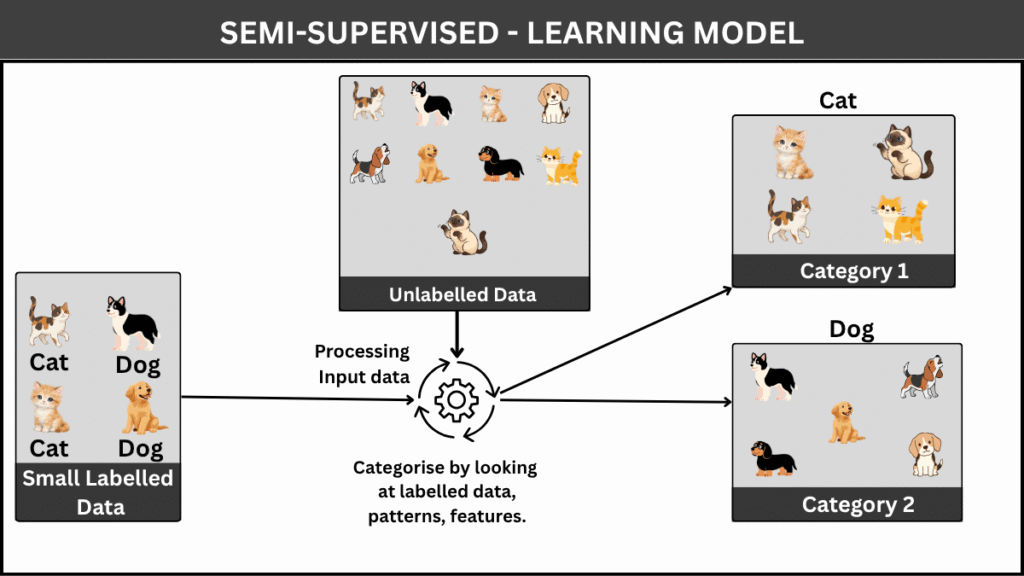
How does it work?
The model is initially trained on a small labeled dataset and then uses patterns learned from unlabeled data to improve its understanding. The underlying assumption is that the structure of the unlabeled data can provide valuable information about the data distribution, helping the model generalize better.
Techniques such as self-training, co-training, and graph-based methods are commonly used to incorporate unlabeled data into the learning process.
The core idea behind semi-supervised learning is:
“Even without labels, data carries structure—and that structure can guide learning.”
When to Use Semi-Supervised Learning
This approach is ideal when:
- Labeled data is limited, but unlabeled data is abundant
- Labeling data is expensive or requires domain expertise
- You want to improve model performance without extensive labeling effort.
4. Reinforcement Learning
Reinforcement learning (RL) is a unique branch of machine learning where an agent learns by interacting with its environment and improving its decisions over time. Instead of learning from labeled data, the model learns through trial and error, guided by rewards and penalties.
The foundations of reinforcement learning come from behavioral psychology and were formalized through concepts like Markov Decision Processes (MDPs) in the mid-20th century. In recent years, RL has gained significant attention due to breakthroughs like game-playing AI systems and robotics, where agents learn complex behaviors from experience.
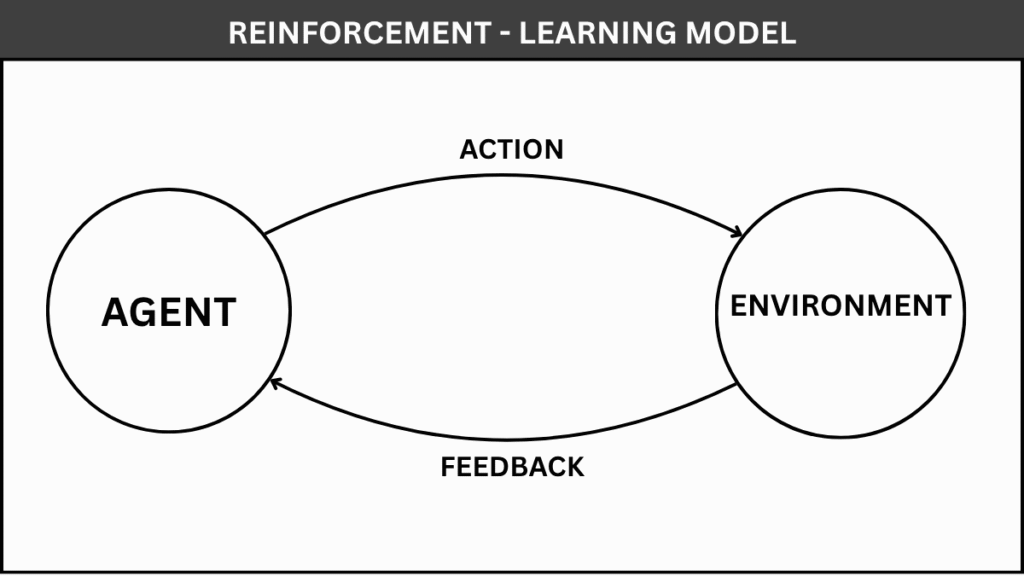
How does it work?
In reinforcement learning, an agent interacts with an environment by taking actions. For each action, it receives feedback in the form of a reward (positive or negative). The objective is to learn a strategy, known as a policy, that maximizes the cumulative reward over time.
The learning process is continuous:
- The agent observes the current state
- Takes an action
- Receives a reward
- Updates its strategy based on the outcome
Over time, the agent improves by favoring actions that yield higher rewards. Some popular reinforcement learning algorithms include: Q-Learning, Deep Q Networks (DQN), SARSA (State-Action-Reward-State-Action)
When to Use Reinforcement Learning
Reinforcement learning is most suitable when:
- The problem involves sequential decision-making
- Actions influence future outcomes
- There is no direct labeled dataset, only feedback signals
- The system can learn through interaction with an environment