
How the “Distillation Revolution” of 2026 is shifting the enterprise focus from parameter count to parameter efficiency.
The 2026 Paradigm Shift: From “God Models” to “Expert Models”
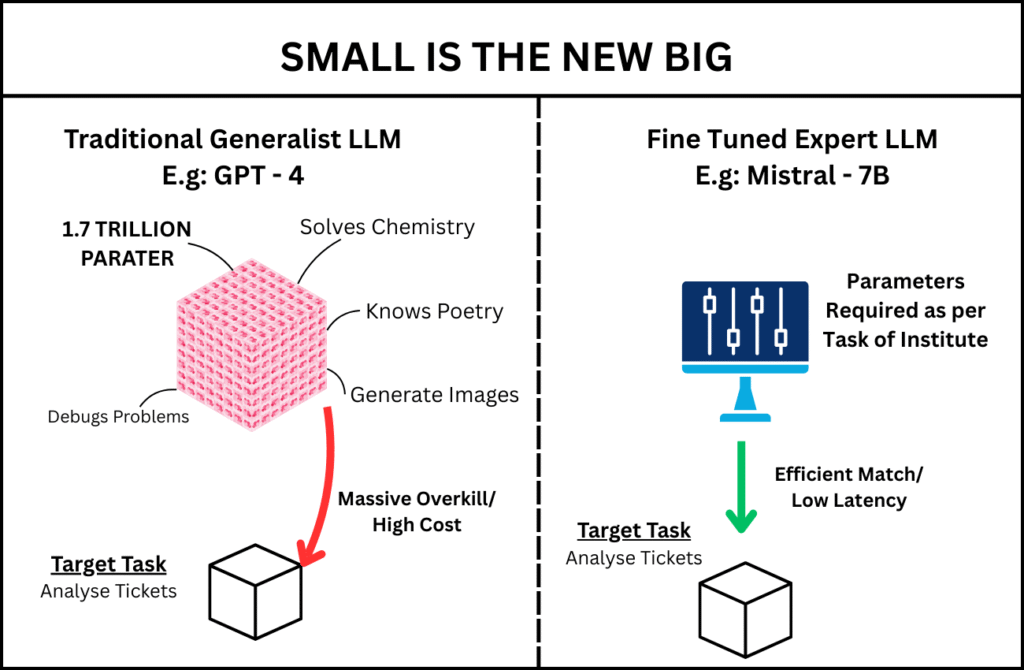
For years, the mantra in Artificial Intelligence was bigger is better. We watched as parameter counts ballooned from billions to trillions, with the industry crowning a new “God Model” a massive, general-purpose LLM that could do everything from writing poetry to debugging legacy COBOL — every few months.
But as we moved into 2026, the honeymoon phase with massive models like GPT-4 ended. Enterprises faced a harsh reality: The Generalist Tax. When you use a 1.7-trillion parameter model to perform a narrow, repetitive task like classifying medical billing codes or routing IT tickets, you are paying for brainpower you don’t need. You are essentially hiring a NASA scientist to count change at a grocery store. It works, but it’s slow, expensive and a massive waste of resources.
In my role as a researcher, I faced this exact dilemma while architecting a support system for a large-scale institution. While I cannot share the proprietary internal data or the specific institutional weights due to strict privacy and security protocols, I have developed a parallel, identical demonstration model to share the findings of this journey. This article is a deep dive into why we transitioned our production pipeline for High-Volume IT Support Ticket Routing from a cloud-hosted frontier model to a locally fine-tuned Mistral-7B variant.
1. The Latency Wall: Why Milliseconds Matter at the Edge
In mission-critical IT environments, AI isn’t just a chatbot; it’s an automated dispatcher. It needs to keep up with the speed of a systems administrator’s operational workflow. If the AI is slower than the human it’s supposed to assist, it becomes technical debt.
The Problem with Cloud Inference
When using a massive cloud-hosted model, your request undergoes a long journey:
- Network Latency: Data travels to the cloud provider’s gateway.
- Queueing Latency: Your request waits in a multi-tenant buffer.
- Compute Latency: The massive model calculates the response across dozens of GPUs.
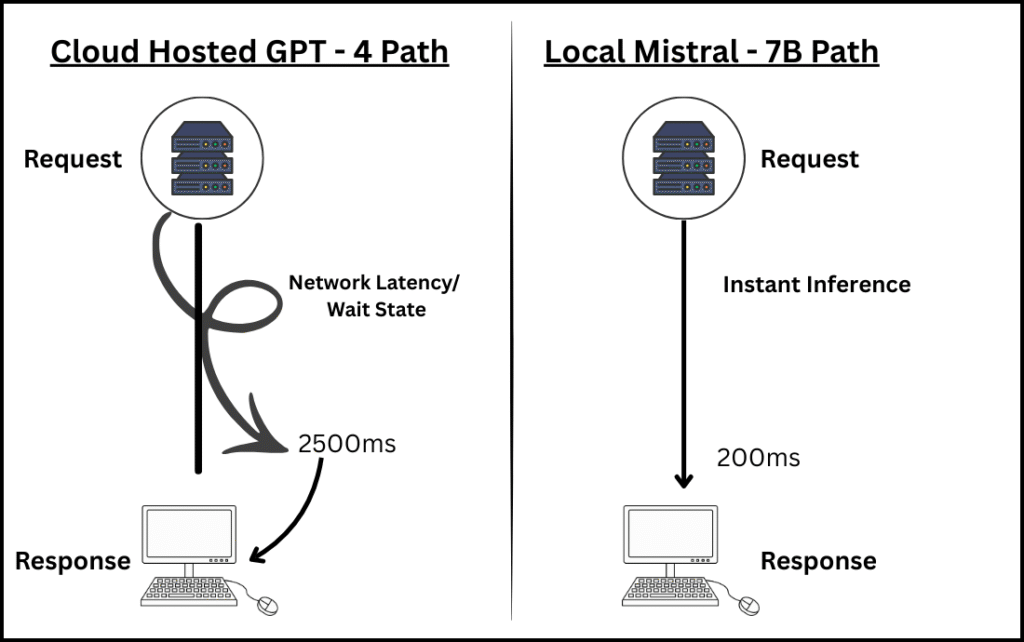
In our institutional testing, GPT-4o averaged a Time To First Token (TTFT) of 850ms. A simple support ticket classification took nearly 2.5 seconds. In a global IT service desk processing 50,000 tickets a day, these seconds aggregate into 34 lost hours per day in mean-time-to-resolution (MTTR).
As illustrated in Figure 2, the difference isn’t just a few milliseconds but it is a fundamental shift in how the data travels. By moving the brain to the edge, we eliminate the spiral of network wait-states shown in the cloud-hosted path
The 7B Alternative: Local Inference
By using a 7-billion parameter model (specifically the Mistral v0.3 architecture), we achieved Local Inference. Because a 7B model can fit into the VRAM of a single consumer-grade GPU, we eliminated the network round-trip. The total response time was under 200ms. Key Takeaway: If your application requires real-time automated dispatching, Bigger isn’t better it’s a bottleneck.
2. The Economics of Scale: Counting the Token Tax
The cost of our deployment is one of the most important considerations. We are always focused on the Total Cost of Ownership (TCO). The variable cost model of cloud APIs is a CFO’s nightmare.
Scenario: Processing 100,000 IT Support Tickets per Day
- GPT-4 (Standard Tier): $5.00 per 1M tokens (Input) + $15.00 per 1M tokens (Output).
- Monthly Estimated Cost: ~$12,000 USD.
The Fine-Tuned SLM (Small Language Model) Cost
By self-hosting our Mistral-7B on a single NVIDIA A100, the cost shifts from Usage to Infrastructure:
- Annual Server Cost: ~$8,000
- Electricity/Maintenance: ~$2,000.
- Total Monthly Cost: ~$833 USD.
By moving to a fine-tuned small model, we reduced our operational costs by over 90% while gaining full control over our data privacy.
3. Accuracy: Does a 7B Model Know Enterprise IT?
The most common counterargument is a 7B model isn’t as smart as GPT-4. This is true for General Intelligence, but General Intelligence is a liability in a specific domain.
The Accuracy Paradox
A 7B model only needs to differentiate between an L2 Database Error and a L1 Password Reset Request.
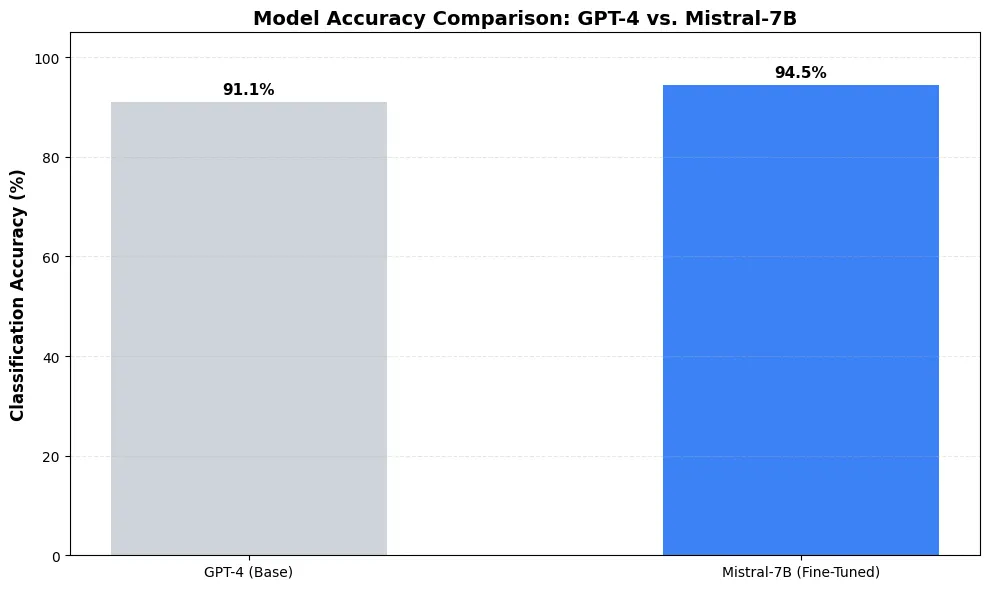
- GPT-4 (Base): 91.1% Accuracy.
- Mistral-7B (Fine-Tuned): 94.5% Accuracy.
Why did the smaller model win? Focus. The fine-tuned 7B model has been over-fitted (in a positive, clinical sense) to our specific vocabulary, acronyms and routing architecture. It no longer guesses but it recognizes patterns with surgical precision.[2]
4. Implementation: The Practitioners Golden Path
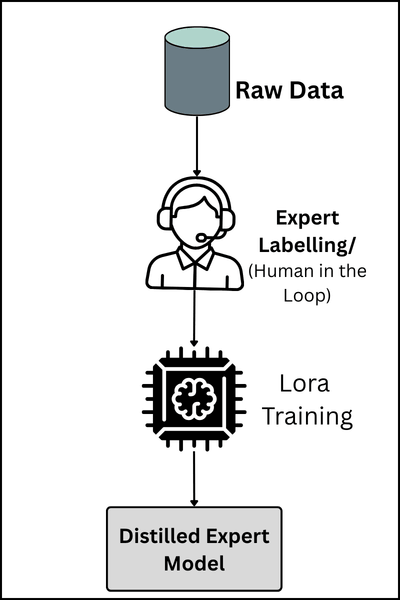
Step A: Data Preparation: Quality distillation begins with structured data. We moved away from long, conversational datasets and focused on a strict Instruction-Output schema. This forces the model to ignore “noise” and focus purely on the mapping between a technical problem and a business action.
For our demonstration model, we utilized a synthetic dataset that mimics the high-stakes environment of corporate IT routing. Each entry follows this precise format:
Note: To comply with institutional security protocols and the EU AI Act’s data minimization principles, the proprietary internal dataset remains private. However, to ensure full reproducibility, I have curated and released a synthetic demonstration dataset that replicates the technical patterns of the production environment. You can take a look at the sample dataset in the HuggingFace link provided below:
Step B: The Training Stack (Unsloth & LoRA): To achieve the 94.5% accuracy benchmark, we utilized Unsloth [3], an optimization library that allows for 2x faster training and 70% less memory usage. We applied Low-Rank Adaptation (LoRA) [1] to the Mistral-7B-v0.3 base model, targeting the attention modules where the expert knowledge resides.
By setting our Rank (r) to 16, we ensured the model was flexible enough to learn complex routing patterns without becoming so heavy that it sacrificed inference speed.
from unsloth import FastLanguageModel
import torch
# 1. Load the model in 4-bit for maximum memory efficiency
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/mistral-7b-v0.3",
max_seq_length = 2048,
load_in_4bit = True,
)
# 2. Add LoRA Adapters (The 'Expert' update)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # The Rank: Determines the 'expressiveness' of the adapter
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha = 16,
lora_dropout = 0,
)
Step C: Verification and Local Deployment: Once trained, the model is exported to GGUF format. This is the final step in the Golden Path, as it allows the model to run on standard CPUs and local hardware without requiring a full Python environment.
You can verify the model’s performance yourself by pulling the live adapters from my repository. The following snippet demonstrates the inference speed we achieved (<200ms):
from unsloth import FastLanguageModel
# 1. Load the model and tokenizer in one go
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "rakshath1/it-support-mistral-7b-expert", # Your adapter
max_seq_length = 2048,
load_in_4bit = True,
)
# 2. Enable faster inference
FastLanguageModel.for_inference(model)
# 3. Test ticket: Regional network failure in Mangalore
ticket_input = "### Instruction:\nTicket: 'VPN access denied for user in Mangalore office.'\n\n### Response:\n"
inputs = tokenizer([ticket_input], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64)
response = tokenizer.batch_decode(outputs)
print(response[0])
Note: While the internal institutional weights remain private, a demonstration model trained on an identical synthetic dataset is available for testing.
- Format: GGUF (for local testing) & Safetensors (for Python integration).
5. The Verdict: Large Models vs. Expert Adapters
I am not saying GPT-4o is bad but it is overqualifiedfor repetitive tasks.
- When to stay Large: Use GPT-4 or other models when you don’t know what the user will ask. If you need a model to reason through a new legal contract it has never seen, you need the massive parameter count of a generalist.
- When to go Small (Experts): Use your fine-tuned 7B model when the task is narrow and high-volume. If you are processing 50,000 IT tickets, which can be repetitive you don’t need the model to know how to write a poem; you need it to know your software inside and out.
6. Conclusion: Small is Sustainable
As we navigate the AI landscape of 2026, it is becoming clear that smaller models are a moral choice just as much as a financial one. The environmental impact of training and running trillion-parameter models is immense; by contrast, a 7B model consumes only a tiny fraction of the power required for a 1.7T model inference. In an era where Green AI is no longer optional, efficiency is the ultimate sophistication.
By choosing to fine-tune, you aren’t settling for less intelligence you are choosing optimized intelligence. You are choosing speed that matches human thought, economics that satisfy a CFO and the sovereignty of owning your own weights. If your organization is still paying five-figure monthly API bills for repetitive classification tasks, you are essentially paying a Generalist Tax that is no longer necessary.
The “Small is the New Big” revolution is about empowerment. It’s about the fact that a researcher can deploy world-class AI on a single GPU. For those interested in testing the latency and accuracy benchmarks for themselves, I have released the LoRA adapters and a GGUF quantized version of this IT Expert on Hugging Face. While the dataset is synthetic to protect institutional privacy, the architecture and the logic remain identical to the production environment. The era of the “God Model” for every task is ending. The age of the Distilled Expert has begun.
References
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, Weizhu. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685. https://arxiv.org/abs/2106.09685
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., & Lample, G. (2023). Mistral 7B. arXiv preprint arXiv:2310.06825. https://arxiv.org/abs/2310.06825
- Unsloth AI. (2024). Performance Benchmarks and Memory Optimization for Fine-Tuning. Unsloth Documentation. https://unsloth.ai/blog/mistral-benchmark